

#2. 기계학습 복습 2
Update Log
| 22.09.13 First Upload
지난 시간에 이어서
인공지능 학습에 앞서서 기계학습에서 배운 내용들을 정리하겠다.
지난 시간에 배운 것들.
일반적으로 기계학습으로 해결하는 문제는 예측 문제이고
이는 회귀와 분류 문제로 나뉜다.
회귀는 실수가 목표치고, 분류는 어떠한 부류로 선택하는 것으로 알려져 있다.
우리가 가지고 있는 데이터뿐만 아니라
우리가 새로운 데이터가 들어왔을 때의 값을 정확하게 예측할 수 있다.
모델링하는 방법
-> 입력과 출력을 잘 나타낼 수 있는 관계를 모델이라고 한다.
이때 파라미터들을 잘 조절할 수 있어야 한다.
간단한 기계학습의 예시.
선형 회귀 문제
우리가 앞서서 살펴봤던 예시는 직선 모델을 사용하는
선형 회귀 문제라고 할 수 있다.

- 직선 모델에서 알아보았둣아 두 개의 매개변수가 존재한다. W와 b이다.
- 이를 벡터로 표현해서 Θ라고 생각하자.
- 기계학습에서도 배웠듯이 목적함수 ( = 비용 함수 = 손실 함수)가 최적의 매개변수의 값을 알 수 있게 한다.
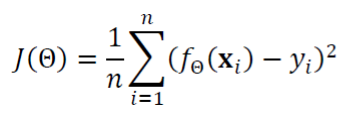
- 선형회귀를 위한 목적함수로, 평균제곱오차 (MSE)를 사용하자.
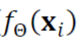
- 아까 이야기했듯이 Θ 는 우리가 구해야 하는 매개변수이다.
- 이때 fΘ(Xi)는 우리가 예측한 함수의 출력이다.
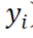
- yi는 예측 함수가 맞추어야 하는 목푯값으로
- 위의 예측 함수에서 예측 함수가 맞추어야 하는 목푯값을 뺀 것이 우리는 오차라고 볼 수 있다.
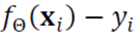
- 따라서 처음에는 최적 매개변수 값을 알 수 없으므로
- 난수로 Θ 값을 지정해주고, 평균 제곱 오차, 즉 손실함수 J(Θ) 를 최대한 줄이는 방면으로 계산해서
- 최적의 Θ, 즉 최적해를 구한다.
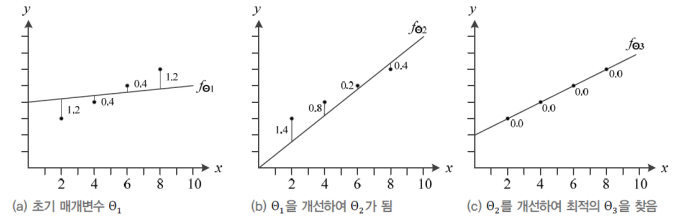
위와 같이 점점 Θ 가 점점 개선되어 최적해를 구할 수 있게 되었다.
결론을 쓰자면 다음과 같다.
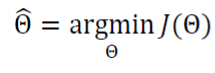
즉 기계학습은 작은 개선을 반복하여 최적해를 찾아가는 수치적 방법으로 식을 푼다.
argmin에 대한 의미
-> min 과의 차이를 먼저 알아야 하는데
min 은 최소, 즉 최솟값 그 자체를 말하는 것이라면
argmin은 최솟값을 만든 변수 값을 리턴해 준다고 생각하면 된다.
위의 식과 같은 경우에는 손실 함수 (평균 제곱 오차)의 값을 최소로 만드는
세타 값을 리턴해서 그 세타 값이 세타 햇이 된다는 것이다.

- 위에서 최적해를 찾아가는 방법을 그냥 구하는 것이 아니라
- 미분, 즉 gradient discent (기울기) 를 통해서 구한다.
- 이는 기계학습 부분을 잘 참고해서 알아보자.
선형회귀모델의 한계
이때 드는 생각은
지금까지는 데이터가 선형을 이루는 아주 단순한 상황을 고려했는데
그렇지 않은 경우도 존재하지 않을까?
결론적으로 이야기하자면 맞다.
실제 세계는 선형이 아니며 잡음이 섞인다.
즉 비선형 모델이 필요한 것이다.

과소 적합과 과잉 적합 (Underfitting, Overfitting)
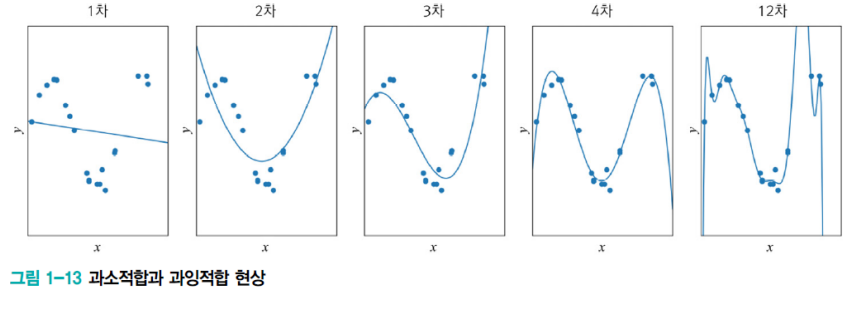
과소적합
- 과소 적합의 정의
- 모델의 용량이 적어서 오차가 클 수밖에 없는 현상을 말한다.
- 여기에서 용량이 적다는 것은 모델의 표현 용량이 작다는 것을 의미한다
- 비선형 모델을 사용하는 대안
- 이는 우리가 아는 다항함수를 생각해 볼 수 있다.
- 2차 3차 혹은 그 이상의 함수들 말이다.
- 위에 있는 그림들은 그 다항식 곡선을 선택한 예시이다.
- 보면 1차(선형)에 비해서 오차가 크게 감소하는 것을 알 수 있다.
- 그렇다면 과소 적합은 어떠한 경우를 말하는 것일까?
- 앞에서 2차 함수를 보면 1차 함수보다는 어느 정도 오차가 작아지지만,
- 그래도 큰 차수들 보다는 용량이 적어서 오차가 클 수밖에 없다.
과잉 적합
- 과잉 적합도 정의
- 용량(Capacity)이 커서, 학습 과정에서 잡음까지 수용하는 현상을 말한다.
- 위의 예시에서 한번 판단해보자
- 12차 다항식 곡선을 보면 훈련 집합에서 거의 완벽하게 근사화하는 것을 알 수 있다.
- 하지만 새로운 데이터를 예측할 때 큰 문제가 발생한다.
- 밑에 그림을 보면서 알아보자.
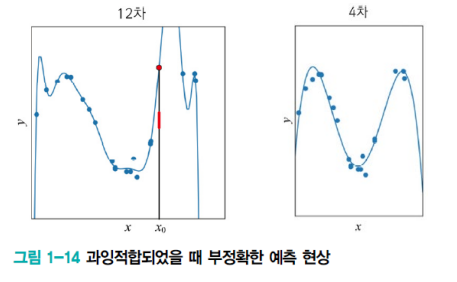
- x0에서 새로운 입력값이 들어왔다고 가정했을 때 ,x0는 빨간 막대 근방을 예측하는 것이 어느 정도 맞다.
- 하지만 이때 과잉 적합을 했을 때는 빨간 점을 예측할 수밖에 없다.
그렇다면 이번 예시를 정리해 보겠다.
- 1~2 차는 훈련 집합과 테스트 집합 모두 낮은 성능을 보인다.
- 12차는 훈련 집합에 높은 성능을 보이나, 테스트 집합에서는 낮은 성능을 보인다.
- 즉, 낮은 일반화 능력을 가진다.
- 3~4차는 훈련집합에 대해서 12차 보다는 낮겠지만, 테스트 집합에는 높은 성능을 보인다.
- 즉, 높은 일반화 능력을 가진다.
- 딥러닝의 경우에는 "규제" 를 사용한다.
- 원래 모델이 갖추고 있던 용량을 줄이는 것이다.
이 내용을 가지고 바이어스와 분산에 대해서 알아보자.
바이어스와 분산
바이어스와 분산
훈련집합 (Training Set)을 여러 번 수집하여 1~ 12 차에 적용하는 실험을 했다고 가정하자.
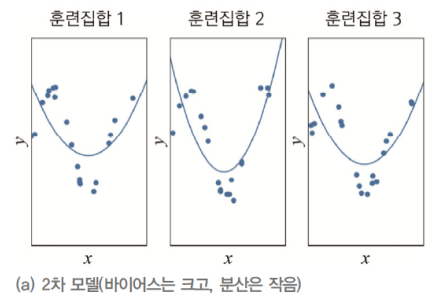
- 다음 그림을 분석해보자면 바이어스가 크다
- 즉 오차들이 크다는 의미이다.
- 하지만 비슷한 모델을 계속해서 얻을 수 있다.
- 이는 즉 낮은 분산을 가지고 있다는 의미이다.
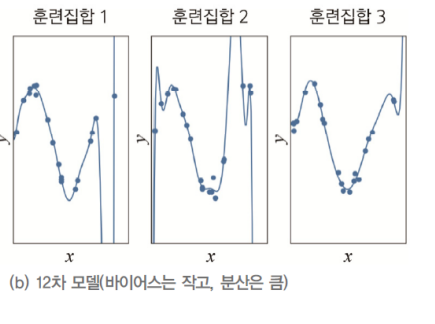
- 이번 그림을 분석해보자면 바이어스가 작다.
- 즉 오차가 매번 작다는 말이다.
- 하지만 다른 모델이 크게 나타난다.
- 즉, 높은 분산을 가지고 있다는 말이다.
- 용량이 적은 모델은
- 바이어스는 크다.
- 분산은 작다.
- 복잡한 모델은
- 바이어스는 작다.
- 분산은 크다.
여기에서 알아둬야 하는 것이
바이어스와 분산은 "트레이드오프" 관계이다.

이를 직관적으로 잘 이해할 수 있는 방법이 다음과 같은 과녁판이다.
총 4개의 그림이 있는데
왼쪽 위부터 오른쪽으로 내려갔을 때 1,2,3,4번이라고 하자.
1번 그림은 높은 바이어스와 , 낮은 분산인 그림이고
2번 그림은 높은 바이어스와 높은 분산을 가지고 있는 그림이다.
3번 그림은 낮은 바이어스와 낮은 분산을 가지고 있는 그림이다.
4번 그림은 낮은 바이어스와 높은 분산을 가지고 있는 그림이다.
기계학습의 목표는
- 낮은 편향과 낮은 분산을 가진 예측 모델을 만드는 것이 목표
- 하지만 모델의 바이어스와 분산은 상충(트레이드-오프) 관계이다.
- 따라서 편향을 최소로 유지하면서 분산도 최대로 낮추는 전략이 필요하다.
검증 집합과 교차 검증을 이용한 모델 선택 알고리즘
위에서 보았던 바이어스의 희생을 최소로 유지하면서
분산을 최대로 낮추는 전략을 사용하기 위해서 2가지의 방법을 알아보자.
검증 집합을 이용한 모델 선택
- 이는 훈련 집합 (Training Set)과 테스트 집합(Test set)과 다른 별도의 검증 집합(Validation set)을 가진 상황이다.
- 데이터의 양이 많은 경우에 검증집합을 사용한다.

교차검증 (Cross Validation)
- 비용의 문제로 별도의 검증 집합이 없는 상황에 유용한 모델 선택 기법이다.
- 데이터 양이 적은 경우에 교차검증집합을 사용한다.
- 훈련 집합을 등분하여, 학습과 평가 과정을 여러 번 반복한 후 평균을 사용한다.
- 아래에서 자세한 과정을 알아보자
- 아래 내용은 K- CrossValidation이다.

부트스트랩 (Bootstrap)
- 이는 난수를 이용한 샘플링의 반복이다.
- 즉 임의의 복원추출의 샘플링 반복이다.
- 데이터 분포가 불균형일때 적용한다.
- 보안 등 이상탐지 문제에서 많이 사용된다.
- 현재 있는 표본에서 추가적으로 표본을 복원 추출하고
- 각 표본에 대한 통계량과 모델을 다시 계산하는 것이며,
- 데이터나 표본 통계량이 정규분포를 따라야 한다는 가정은 꼭 필요하지 않다.
- 즉, 원래 표본을 수천, 수백만 번 복제하는 것이라고 할 수 있다.
- 이를 통해 원래 표본으로부터 얻어지는 모든 정보를 포함하는 가상 모집단을 얻을 수 있다.
아래와 같이 알고리즘을 이용하면서 따라가 보자.

모델 선택의 한계와 현실적인 해결책
사실상 모델 선택의 한계가 있다.
- 우리가 지금까지 보아왔던 예시들은 서로 다른 차수의 다항식이 모델 집합이라고 할 수 있다.
- 하지만 현실에서는 아주 다양하다
예시를 들어보자면
- 신경망, 강화 학습, 확률 그래피컬 모델, SVM, 트리 분류기 등이 선택 대상이다.
- 신경망을 채택하더라도 MLP, Deep MLP, CNN 등 아주 많다.
그렇다면 현실에서는 어떻게 할까?
- 현실에서는 경험으로 큰 틀을 선택한 후 모델 선택 알고리즘으로 세부 모델을 선택하는 전략을 사용한다.
- 예시를 들어보자면,
- CNN을 사용하기로 정한 후, 은닉층 개수, 활성 함수, 모멘툼 계수 등을 정하는데
- 모델 선택 알고리즘을 적용한다.
- 또한 용량이 충분히 큰 모델을 선택한 후, 선택한 모델이 정상을 벗어나지 않도록 여러 가지 규제 기법을 적용한다.
기계학습의 유형
기계학습의 유형
이는 너무 많이 나오는 부분이라서
간단하게만 정리하겠다
지도 방식에 따른 유형
지도 학습
- 특징 벡터 x와 목푯값 Y가 모두 주어진 상황을 말한다.
- 회귀와 분류 문제로 구분된다.
비지도 학습
- 특징 벡터 X는 주어지는데 목푯값 Y 가 주어지지 않는 상황
- 전에 들어봤듯이 군집화(Clustering)에 이용된다.
- 밀도 추정, 특징 공간 변환에 이뤄진다.
강화 학습
- 목푯값이 주어지는데, 지도 학습과 다른 형태이다.
- 이는 예시를 들으면서 알아보는 게 좋을 것 같다.
- 바둑 같은 경우가 강화 학습의 예시라고 할 수 있는데
- 수를 두는 행위가 샘플인데, 게임이 끝나면 목푯값 하나가 부여된다.
- 이기면 1 패배하면 -1을 부여한다.
- 게임을 구성한 샘플들 각각에 목푯값을 나누어 주어야 한다.
준지도 학습
- 일부는 X와 Y를 모두 가지지만 나머지는 X만 가진 상황이다.
- 인터넷 덕분으로 X의 수집은 쉽지만, Y는 수작업이 필요하여 최근에 중요성이 부각되었다.
다양한 기준에 따른 유형
오프라인 학습과 온라인 학습
- 오프라인은 데이터가 다 수집된 학습이라고 할 수 있다.
- 반면 온라인 학습은 계속 데이터가 들어오면서 하는 학습이라고 할 수 있다.
- 다시 이야기하면 온라인 학습은 인터넷 등에서 추가로 발생하는 샘플을 가지고
- 점증적인 학습을 한다고 생각하면 된다.
결정론적 학습과 스토캐스틱 학습
- 결정론적 학습에서는 같은 데이터를 가지고 다시 학습하면 같은 예측기가 만들어진다.
- 반면, 스토캐스틱 학습은 학습 과정에서 난수를 사용하므로,
- 같은 데이터로 다시 학습하면 다른 예측기가 만들어진다
- 보통 예측 과정도 난수를 사용한다.
- 예 ) RBM, DBN
분별 모델과 생성 모델
- 분별 모델은 부류 예측에만 관심이 있다.
- 생성 모델은 사람 얼굴을 만드는 것과 같이 새로운 데이터를 만드는 것이다.
- 즉 요즘 나오는 ai가 그려주는 그림이 이와 같은 예시이다.
'STUDY > 인공지능' 카테고리의 다른 글
| #6. 다층 퍼셉트론 및 딥러닝 기초 (0) | 2022.11.01 |
|---|---|
| #5. 최적화 이론 (1) | 2022.11.01 |
| #4. 기계학습 수학2 (1) | 2022.11.01 |
| #3. 기계학습 수학 1 (0) | 2022.11.01 |
| #1. 기계학습 복습 1 (1) | 2022.11.01 |




