

#5. 최적화 이론
Update Log
| 22.09.22 First Update
| 22.10.12 Second Updatee
이번 포스트에서 알아볼 내용은
최적화 이론이다.
최적화 이론이라는 것은 무엇일까?
간단하게 말하면 최적의 선택을 하는 것이다.
이때 무엇이 "최적" 일까?
모든 가능해 집합에서의 x 중 함수 f(x)를 최소화(혹은 최대화) 하는 x를 찾는 것을 말한다.
아래의 식을 보고
이제 최적화 문제의 수학적 표현을 알아보자.

위 식에 있는 표현들을 좀더 꼼꼼히 알아보자.

순수 수학 최적화와 기계 학습 최적화의 차이
순수수학의 최적화
- 순수수학에서의 최적화는 함수에서 최저점, 최고점을 찾는 방법을 말한다.
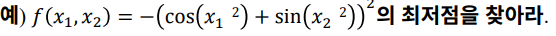
기계학습의 최적화
- 기계 학습의 최적화는 단지 훈련 집합이 주어지고, 훈련 집합에 따라 정해지는 목적 함수의 최저점으로 만드는 모델의 매개변수를 찾아야 한다.
- 이때 데이터로 미분하는 과정이 필요하다.
- 예) 오류 역전파 알고리즘 (Back Propagation)
- 주로는 SGD(스토캐스틱 경사 하강법)을 사용한다.
- 이는 손실함수를 미분하는 과정이 필요하다.
- 오류 역전파 알고리즘 기계 학습의 최적화는 순수 수학 최적화 보다 어렵다.
- 최적해가 보장되지 않는다.
선형회귀 (Linear Regression)에서의 예시다.

여기에서 목적은
평균제곱오차 (MSE)를 최소화하는 직선의 매개변수 a, b를 찾는 최적화 문제이다.
이를 식으로 표현하면 다음과 같다.
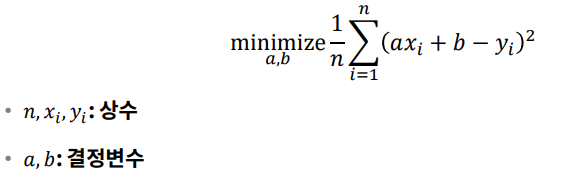
매개변수 공간의 탐색
- 특징 공간의 높은 차원에 비해서 훈련집합의 크기가 작아서 참인 확률 분포를 구하는 일은 사실상 불가능하다.
- 여기서 참인 확률분포라는 것은, 모든 확률을 나타내는 확률분포라고 생각하면 된다.
- 따라서 기계학습은 적절한 모델을 선택하고, 목적함수를 정의하고, 모델의 매개변수 공간을 탐색하여
- 목적함수가 최저가 되는 최적점을 찾는 전략을 사용한다.
- 즉, 특징 공간에서 해야 하는 일을 모델의 매개변수 공간에서 하는 일로 대치한 셈이다.
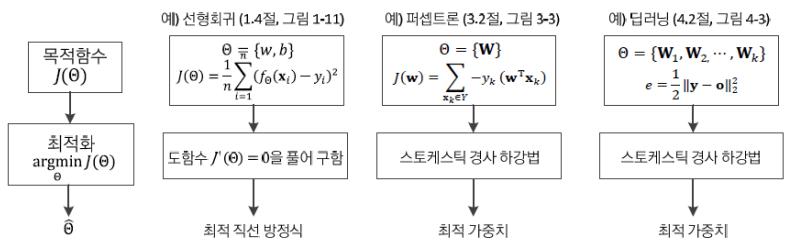
- 선형회귀
- 목적함수의 도함수가 0이 됨을 풀어서 구한다
- 이를 통해서 최적 직선 방정식을 구한다.
- 퍼셉트론
- 스토케스틱 경사하강법을 통해서 구한다.
- 이를 통해서 최적 가중치를 구한다.
- 딥러닝( 파라미터의 개수가 더 많아진다.)
- 스토케스틱 경사하강법을 통해서 구한다.
- 이를 통해서 최적 가중치를 구한다.
학습 모델의 매개변수 공간
- 이 매개변수공간은 특징 공간보다 수배~ 수만 배 넓다.
- MNIST 인식하는 심층학습 모델은 784차원의 특징공간을 가지고 있다.
- 하지만 매개변수 공간은 수십만 ~ 수백만 차원의 매개변수 공간이다.
- 선형 회귀에서는 특징 공간은 1차원, 매개변수는 2차원이다.
- 전역 최적해에 가까운 지역 최적해를 찾고 만족하는 경우가 많다.
- 손실함수 값의 미분값을 음수로 취한것이 작아지도록 한다.

- 다음과 같은 개념도의 매개변수 공간은 전역 최적해와 지역 최적해로 나눌 수 있다.
- x hat은 전역 최적해이고, x2, x4는 지역 최적해이다.
- x2와 같이 전역 최적해에 가까운 지역 최적해를 찾고 만족하는 경우가 많다.
결론적으로 기계 학습이 해야 할 일을 식으로 정의하면

최적화 문제 해결 알고리즘 몇 개를 알아보자
낱낱 탐색 (Exhaustive Search) 알고리즘
- 차원이 조금만 높아져도 적용이 불가능하다.
- 모든 가능한 파라미터 공간을 다 탐색한다.
- 예) 4차원 Iris에서 각 차원을 1000구간으로 나눈다면 총 1000 ^4 개의 점을 평가해야 한다.

무작위 탐색 (Random Search) 알고리즘
- 아무 전략이 없는 순진한 알고리즘

기계학습이 사용하는 전형적인 알고리즘
(목적함수가 작아지는 방향을 미분을 통해 구하는 알고리즘)

미분
그렇다면 이제 미분에 대해서 알아보자.
미분에 의한 최적화
미분의 정의부터 보면

- 1차 도함수는 함수의 기울기, 즉 값이 커지는 방향을 지시한다.
- 따라서 -f'(x) 방향에 목적함수의 최저점이 존재한다.
- 아까 위에서 바로 보았던 기계학습 알고리즘에서 d(Θ)로 -f'(x)를 사용한다.
- 이것이 경사 하강 알고리즘의 핵심 원리이다.
편미분
- 편미분이란 변수가 여러 개인 함수의 미분이다.
- 이때 미분 값이 이루는 벡터를 그래디언트(경사도)라고 부른다.
- 표기를 잘 알아보자.

- 기계학습에서의 편미분
- 매개변수 집합 Θ 에 많은 변수가 있으므로 편미분을 많이 사용한다.
독립변수와 종속변수
- y = wx + b
- x는 독립변수, y는 종속 변수라는 것을 알 수 있다.
- 하지만 기계학습에서는 이런 해석은 무의미하다.
- 왜냐하면 예측 단계를 위한 해석에 불과하기 때문이다.
- 최적화는 예측 단계가 아니라 학습단계에 필요하다.
- Θ가 독립변수이고 error 가 종속변수이다.
- 즉, 세타값을 잘 조정해서 에러값을 최적화 해야한다.
야코비언 행렬

- 각 요소를 1차 편미분 한 것이다.
헤시안 행렬
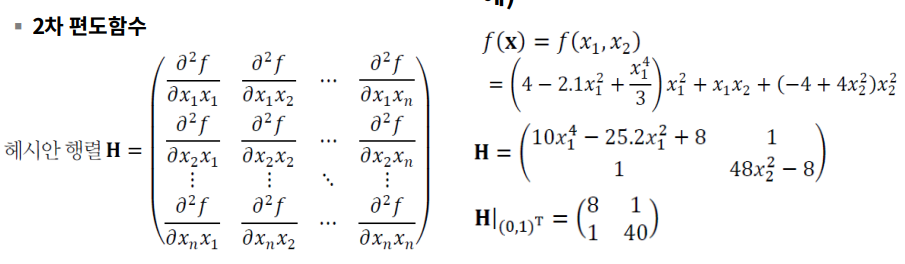
- 각 요소를 2차 편미분 한 것이다.
- 2차 편도함수라고 불린다.
경사하강 알고리즘

- 손실함수를 매개변수 Θ 로 미분한 것이 그래디언트이다.
- 함수의 그래디언트를 구하여 그래디언트가 낮은쪽으로 반복적으로 이동하여 최솟값에 도달한다.
Batch 경사 하강 알고리즘

- 샘플의 경사도를 구하고 평균한 후 한꺼번에 갱신한다.
- 훈련집합 전체를 다 봐야 갱신이 일어나므로 학습 과정이 오래 걸리는 단점이 있다.
- 갱신을 한번 하기 위해서 데이터셋을 다 집어넣고 나온 손실함수를 또 미분해서 갱신하기 때문이다.
SGD 하강 알고리즘

- 일반적으로 더 많이 쓰이는 경사하강 알고리즘이다.
- 한 샘플 혹은 작은 집단 (무리, mini batch) 의 경사도를 계산한 후에 즉시 갱신한다.
- mini batch: 3~6번째 줄을 한 번 반복하는 일을 epoch 라고 부른다.
경사하강 알고리즘 비교
- 집단 경사 하강 알고리즘 (Batch)
- 정확한 방향으로 수렴한다.
- 느리다.
- 확률론적 경사 하강 알고리즘 (SGD)
- 수렴이 다소 헤맬 수 있다.
- 빠르다
'STUDY > 인공지능' 카테고리의 다른 글
| #7. 딥러닝과 깊은 퍼셉트론 (0) | 2022.11.01 |
|---|---|
| #6. 다층 퍼셉트론 및 딥러닝 기초 (0) | 2022.11.01 |
| #4. 기계학습 수학2 (1) | 2022.11.01 |
| #3. 기계학습 수학 1 (0) | 2022.11.01 |
| #2. 기계학습 복습 2 (1) | 2022.11.01 |




