

#1. 기계학습 복습 1
Update Log
| 22.09.13 First Upload
| 22.10.11 Second Upload
기계학습 개념
기계학습의 개념
간단한 기계학습의 예제

- 이 문제에서 가로축은 시간, 세로축은 이동체의 위치이다.
- 그림에서 보이는 4개의 점이 데이터라고 할 수 있다.
- 기계학습은 결국 예측의 문제라고 할 수 있다.
- 임의의 시간이 주어지면 이때 이동체의 위치를 물어본다고 가정하자.
- 그렇다면 이 문제는 '회귀' 문제라고 할 수 있다.
- 즉 회귀 문제는 목표치가 "실수"
- 분류 문제는 "부류 값"이라고 할 수 있다.
훈련 집합 (Training Set)
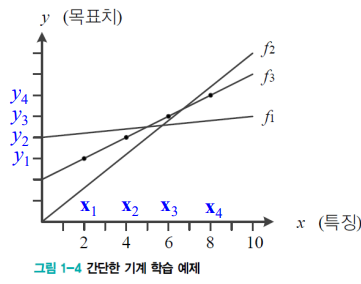
- 이 문제에서 가로축은 특징 (Feature) ,세로축은 목표치 (Label)이라고 할 수 있다.
- 다음 그림에서는 특징이 한 개다.
- 즉 Feature 정보가 1개라고 할 수 있다.
- 관측한 4개의 점이 훈련 집합을 구성할 수 있는데
- 훈련집합을 표현해 본다면 다음과 같이 집합으로 표현할 수 있다.

- x가 두꺼운 이유는 벡터이기 때문이다.
- y가 얇은 이유는 스칼라이기 때문이다.
그림 예제에서 훈련 집합은 다음과 같다.

정리해보자면
- 훈련 집합을 가지고 데이터를 모델링 한 후 이를 통해서 매개변수를 조절한다고 생각하면 된다.
- 그럼 훈련집합 부분은 끝났다고 보면 데이터를 어떻게 모델링을 할까?
- 앞에서의 문제는 눈대중으로 보면 직선을 이루므로 직선을 선택한 것이다.
- 따라서 모델로 직선을 선택한 셈이다.
- 직선 모델의 수식은 다음과 같다.
- 두 개의 매개변수가 있는데
- w와 b
- y = wx + b
- 즉 기계학습은 가장 정확하게 예측할 수 있는 최적의 매개변수를 찾는 작업이다.
- 처음에는 최적 값을 모르므로 임의의 값에서 시작하고 점점 성능을 개선하여 최적에 도달하는 것이다.
그렇다면 기계학습의 궁극적인 목표는 무엇일까?
- 훈련 집합에 없는 새로운 샘플에 대한 오류를 최소화하는 것이다.
- 이 새로운 샘플, 즉 테스트 집합에 대한 높은 성능을 "일반화 (Generalization) 능력"이라고 부른다.
결론을 내리자면 기계학습의 필수요소는
- 학습할 수 있는 데이터가 있어야 한다.
- 데이터 안에 규칙이 존재해야 한다.
- 수학적으로 설명이 불가능 해야 한다.
특징 공간 (Feature Space)
1차원과 2차원 특징 공간
모든 데이터는 정량적으로 표현되며, 특정 공간 상에 존재한다.
1차원 특징공간

- 위에서 들었던 예시를 특징 공간에 표시하면 왼쪽 그림과 같다.
- 이때 특징만 축으로 표시를 하게 되면 오른쪽 그림과 같아진다.
2차원특징공간
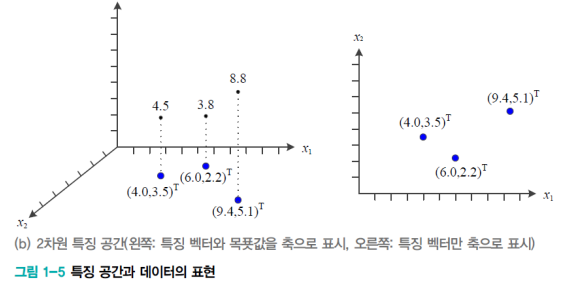
- 특징 공간이 2개인 경우는
- 다음과 같이 목푯값과 같이 표시할 때는 3차원의 공간이 필요하다
- 특징 벡터만 축으로 표시할 경우에는 오른쪽 그림과 같아진다.
- 이때 오른쪽 그림에서 나에게로 기둥이 솟아오른다고 생각하면 편할 것이다.
- 특징 벡터 표기와 예시를 들어보자면 다음과 같다.

다차원 특징공간
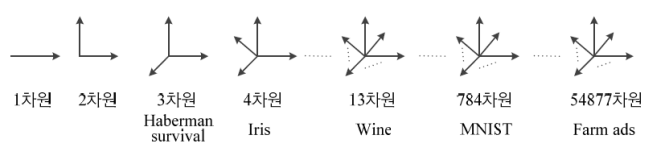
- 앞으로 여러 가지의 특징 공간, 데이터셋을 다룰 것인데 이에 대한 예시는 다음과 같다.
- Iris 데이터셋은 4차원 공간 데이터 셋
- 3차원 이상의 특징공간
- 이미지 동영상
- 우리 입장에서 숫자의 추가는 기계학습에서의 차원의 확장이다.

그렇다면 예시 말고도 표기를 어떻게 하는지도 알아보자.
d- 차원 데이터
d차원의 데이터가 있다고 가정했을 때
d차원의 특징 벡터는 다음과 같다.
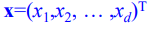
이때 d차원 데이터를 위한 학습모델을 보면
직선 모델
직선 모델을 사용하는 경우에는 매개변수의 수가 d+1 개다.

2차 곡선 모델
2차 곡선 모델을 사용하면 매개변수의 수가 크게 증가한다.
이때 매개변수의 수는 d^2 + d+ 1
예시를 들어보자면 Iris 데이터는 d = 4이므로 21개의 매개변수가 있다.

차원의 저주
- 차원이 높아짐에 따라서 발생하는 현실적인 문제들을 말한다.
- 우리에게는 하나의 숫자의 추가 일지 모르지만 사실상 지수적으로 다뤄야 하는 계산이 많아진다.
- 예를 들어보면 위에서 들었던 예시처럼
- d = 4 인 iris 데이터에서 축마다 100개의 구간으로 나누면 100^4으로 1억 개의 칸이 나온다.
- 1차원을 5개의 데이터로 채워서 규칙을 찾는것은 쉽다.
- 3차원을 5개의 데이터로 채워서 규칙을 찾는것은 어렵다.
특징 공간 변환과 표현 학습
특징 공간 변환
특징 공간을 변환하는 이유는
학습을 하는데 유리한 부분으로 변형하기 위해서이다.
만약 선형 분리 불가능한 원래 특징 공간이 있다고 가정하자.
다음 그림을 보자

- 다음 그림에서는 직선 모델을 적용하면
- 아무리 선을 그어봐도75% 정확률이 한계이다.
이것을 해결하는 방법은 어떠한 것이 있을까
- 특징 공간을 변환하는 방법이 있다.
- 위의 예시에서 다음과 같이 특징 벡터를 바꾸어 보면 다음과 같다.

다음 계산을 통해서 분류에 더 유리하도록
특징 벡터를 변환해 표현한 특징 공간은 다음과 같다.

공간이 변형되고, 그 안에서부터 공간이 변형될 수 있는 규칙을 새롭게 정의하면
우리가 원 공간에서 제대로 해결하지 못했던 문제들을 제대로 표현 할 수 있다.
우리는 이를 "표현 문제" 라고 한다.
데이터가 특징공간안에 있는 구조적인 표현 자체를 "Representation" 이라고 한다.
Representation 을 배우고 활용해서 공간변환으로 문제를 해결하는 것을
우리는 "표현 문제" 라고 한다.
표현학습
- 표현 학습은 좋은 특징 공간을 자동으로 찾는 작업이다.
- Input -> Representaion -> Output
딥러닝 (심층학습)
- 다수의 은닉층을 가진 신경망을 이용하여 계층적인 특징 공간을 찾아낸다.
- 계층적인 특징 공간을 찾는 이유는 예측에 유리하게 하기 위해서이다.
- 간단한 표현부터 추상화된 표현까지 세분화해서 계층적으로 학습을 하는것이 일반적인 표현학습과의 차이이다.
- 왼쪽 은닉층(아래쪽 은닉층) 은 저급 특징 (에지, 구석점)을 추출한다
- 오른쪽 은닉층 (위쪽 은닉층)은 고급 특징(얼굴, 바퀴 등)을 추출한다.
- Image, text, speech 모든 분야에 쓰일 수 있다.
- 문제를 푸는데 더 효과적이다.
데이터에 대한 이해

- 과학기술의 정립의 과정은 다음과 같다.
- 데이터의 수집 -> 모델 정립(가설) -> 예측 -> 반복...
- 기계학습이 푸는 문제는 이와 같은 것보다는 훨씬 복잡하다.
- 단순한 수학 공식으로는 표현이 불가능하다
- 즉, 자동으로 모델을 찾아내는 과정, 데이터를 설명할 수 있는 학습모델을 찾아내는 과정이 필수인 것이다.
- 예시를 한번 들어보자.
- 데이터 생성과정을 완전히 아는 예제와 기계학습의 예제를 보자.
- 두 개의 주사위를 던져 나온 눈의 합을 x라고 할 때, y = x+1을 받는 게임
- 이러한 상황을 데이터 생성 과정을 완전히 알고 있다고 말한다.
- 즉 x를 알면 정확히 y를 예측할 수 있다.
- x의 발생 확률 P(x)를 정확히 알 수 있다.
- 이는 새로운 데이터도 생성이 가능하다.
- 기계학습과 같은 문제는
- 데이터의 생성 과정을 전혀 알 수 없다.
- 단지 주어진 훈련 집합 x, y로 예측 모델 또는 생성 모델을 근사 추정할 수 있을 뿐이다.
- 두 개의 주사위를 던져 나온 눈의 합을 x라고 할 때, y = x+1을 받는 게임
- 데이터 생성과정을 완전히 아는 예제와 기계학습의 예제를 보자.
데이터베이스의 중요성
데이터베이스
- 데이터베이스는 우리가 많이 들었던 데이터 셋이라고 할 수 있다.
- 데이터베이스의 품질
- 주어진 응용에 맞는 충분히 다양한 데이터를 충분한 양만큼 수집하면 추정 정확도가 높아진다.
- 예를 들어 정면 얼굴만 가진 데이터 베이스로 학습하고 나면 기운 얼굴은 매우 낮은 성능을 보인다.
- 주어진 응용에 맞는 충분히 다양한 데이터를 충분한 양만큼 수집하면 추정 정확도가 높아진다.
- 많은 공개 데이터베이스
- 기계학습의 초파리로 여겨지는 3가지 데이터베이스:
- Iris, MNIST, ImageNET 3가지가 있다.
- 이때 MNIST 데이터셋을 예시로 들고 다음 그림을 보자

- 데이터의 적은양은 '차원의 저주' 와 관련이 있다.
- MNIST 데이터 셋은 28*28 픽셀로 단순히 흑백(=2)으로 구성된다면 각각의 픽셀은 차원(특징)이다
- 그렇다면 서로 다른 총 샘플 수는2^784가지이지만, MNIST는 고작 6만 개 샘플
- 결국에는 방대한 데이터 공간에 희소한 데이터 영역만 채워진다.
- 차원의 저주 관점에서 보면 규칙을 제대로 찾을 수 없다.
- 하지만 MNIST는 규칙을 잘 찾는다.
- 적은양의 데이터베이스로 높은 성능을 얻는 이유
- 방대한 공간에서 실제 데이터가 발생하는 곳은 매우 작은 부분 공간이다.
- 즉 데이터 희소 (data Sparsity) 특성을 가정한 것이다.
- 전체 데이터셋에서 주목해야 하는 것은 확률 분포이다.
- 의미 없는 데이터는 확률을 거의 0으로 수렴하고
- 의미 있는 데이터는 확률이 높아진다고 생각하면 된다
- 전체 데이터셋에서 주목해야 하는 것은 확률 분포이다.
- 매니폴드가정 (Manifold Assumption or Manifold Hypothesis)
- 고차원의 데이터를 저차원에서 바라보는 관점이다.
- 고차원의 데이터는 관련된 낮은 차원의 매니폴드에 가깝게 집중이 되어있다.
- 차원의 저주 관점에서 보면 MNIST는 제대로 학습이 이뤄질 수 없다.
- 하지만 학습이 잘 이뤄지는 이유는 내재되어있는 고차원의 데이터를 발현할 때
- 특정한 규칙에 의해 발현되기 때문이다.
- MNIST 데이터 셋에서는 우리가 모서리 부분에 있는 데이터들은 전혀 쓰지 않으므로..
데이터 가시화
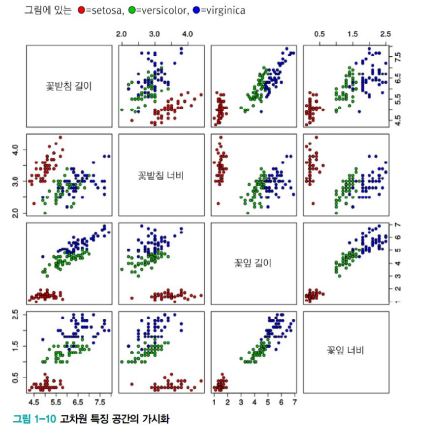

- 4차원 이상의 초공간은 한꺼번에 가시화가 불가능
- 여러가지의 가시화 기법이 있다.
- 위의 그림들은 2개씩 조합하여 여러개의 그래프 그림을 만든것.
- 고차원 공간을 저차원으로 변환하는 기법들
- 매니폴드를 잘 찾으면 고차원의 특징들을 저차원에서도 잘 보존할 수 있다.
'STUDY > 인공지능' 카테고리의 다른 글
| #6. 다층 퍼셉트론 및 딥러닝 기초 (0) | 2022.11.01 |
|---|---|
| #5. 최적화 이론 (1) | 2022.11.01 |
| #4. 기계학습 수학2 (1) | 2022.11.01 |
| #3. 기계학습 수학 1 (0) | 2022.11.01 |
| #2. 기계학습 복습 2 (1) | 2022.11.01 |




