

#9. 딥러닝 주요 최적화 방법
Update Log
| 22.10.06 First Upload
| 22.10.11 Second Upload
지난 포스팅에서..
그동안 배워왔던 퍼셉트론의 개념을
실습으로 푸는 시간을 가졌다.
오늘부터는 딥러닝 주요 최적화 방법을 배우겠다.
평균 제곱 오차 다시 생각하기
일단 시험을 예시로 들어보자
시험에서는 틀린 만큼 합당한 벌점을 받는 것이 중요하다.
그래야 다음 시험에서 틀리는 개수를 줄일 가능성이 크기 때문이다.
만약 틀린 개수에 상관없이 비슷한 벌점을 받는다면
나태해져 성적을 올리는 데 지연이 발생할 것이다.
이러한 원리를 기계학습에도 적용하자.
평균제곱오차 목적함수
일단 분류 문제를 푼다고 가정해보자
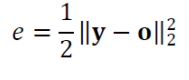
다음과 같이 오차를 정의하면
오차가 클수록 e값이 크므로 이 값은
벌점으로서는 훌륭하다.
즉 손실 함수로써는 문제가 없다.
하지만 여기에는 큰 허점이 존재한다.
다음의 그림을 보자.

- 여기에서 왼쪽 상황은 e = 0.2815이고 오른쪽의 상황은 e = 0.4971 이다.
- 오른쪽이 사실상 더 큰 벌점을 받아야 마땅하다.
- 하지만 오른쪽에 gradient를 보다 왼쪽보다 훨씬 더 느리게 진행되는 것을 알 수 있다.
- 즉, 학습이 느리게 된다는 오류가 발생하는 것이다.
- 신경망 학습 과정에서 학습은 오류를 줄이는 방향으로 가중치와 편향을 교정한다.
- 하지만 이 문제에서는 큰 교정이 필요함에도 작은 경사도로 작게 갱신된다.
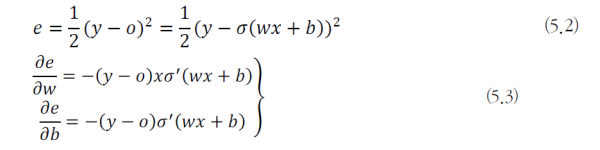
- 우리는 이 그레디언트를 벌점에 해당한다고 생각할 수 있고
- 이때 그레디언트를 계산해보면 왼쪽 상황에 그레디언트가 크다.
- 이는 더 많은 오류를 범한 상황이 더 낮은 벌점을 받은 꼴이 된 것이다.
- 즉 학습이 더딘 부정적인 효과를 낳는다는 것이다.
그렇다면 이러한 결과의 이유는 무엇일까?
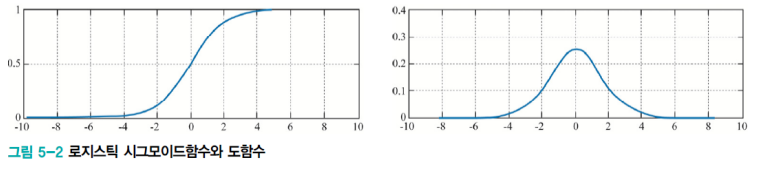
- 그 이유를 생각해보면 wx+b의 값이 (즉, 가로축이) 커지면 커질수록 기울기인 그레디언트가 작아지기 때문이다.
- 따라서 큰 벌점을 부과하더라도 이에 대한 갱신이 더뎌진다.
- 위의 문제를 해결하기 위해서는
- 첫번째로 활성함수를 ReLU로 교체한다.
- 두번째로 MSE를 다른 목적함수, 교차 엔트로피로 바꾼다.
교차 엔트로피 목적함수 (Cross Entropy)
그렇다면 목적함수를 어떻게 설정하는 것이 좋을까
먼저 우리는 분류문제를 가정했기 때문에
이진 분류문제를 이진 교차 엔트로피로 해결한다고 생각해보자
교차엔트로피

- 레이블에 해당하는 y가 확률변수라고 가정하자.
- 이때 부류가 2개라고 가정하면 y = 0 또는 1이다.
- 이때 위에 그림에서 P는 정답인 레이블 , Q는 신경망의 출력이라고 하자.
- 이를이 확률분포를 식으로 다시 표현하면 아래와 같다.
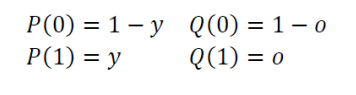
- 이때 신경망 출력으로 표기하면 다음과 같다.
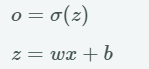
- 이를 통해서 교차 엔트로피의 식은 다음과 같이 표현할 수 있다.
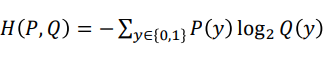
- 교차 엔트로피를 사용하면
- 잘못된 학습으로 오분류된 손실은 (벌점, 오차) 를 무한대에 가깝게 크게 준다.
- 잘된 학습으로 제대로 분류된 손실은 0 으로 나온다.
- 또한 이를 통해서 교차 엔트로피의 목적함수는 다음과 같이 표현할 수 있다.

- 이제 앞에서 MSE를 목적함수로 사용했을 때와 비교를 해보자
- 이 함수가 목적함수로써 제구실을 하는지 확인하는 것이다.

- 일단 에러 적인 측면에서는
- 다음과 같이 예측인 잘 된 경우에는 e는 낮은 값이 나온다.
- 예측이 엉터리인 경우에서는 e값이 커지는 것을 확인할 수 있었다.
- 그렇다면 이제 공정한 벌점 ,즉 그레디언트 부분을 살펴보자
- 아까도 이야기를 했다시피 오류가 커지면 , 그에 따라 그레디언트도 커져야 한다.
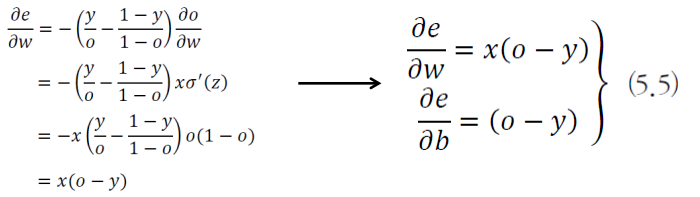

결론적으로 그레디언트를 계산해 보면
오류가 더 큰 오른쪽에 더 큰 벌점( 그레디언트)을 부과했다.
위와 같은 경우는 Binary Classification 문제였고
이제는 이진 분류가 아닌, 3개 이상의 분류 문제는
다음과 같이 확장시킬 수 있다.
즉 출력 벡터를 2개가 아닌

다음과 같이 확장한 것이다.
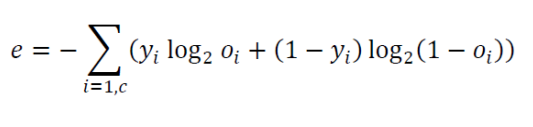
성능 향상을 위한 요령
데이터 전처리
첫 번째로 알아볼 문제는 규모 문제이다.

- 1.855 * w1과 65.5 * w2는 규모의 차이가 100배 가 있기 땜누에 의존성이 많이 생긴다.
- 위의 예시에서는 몸무게에 연결된 가중치의 갱신이 키에 연결된 가중치보다 훨씬 크게 변한다.
- 따라서 불균형하게 학습된다.
즉 이를 정리하면 다음과 같다.

따라서 데이터의 규모 (Scale, 단위)를 비슷하게 맞춰야 한다.
모든 특징이 양수인 경우의 문제
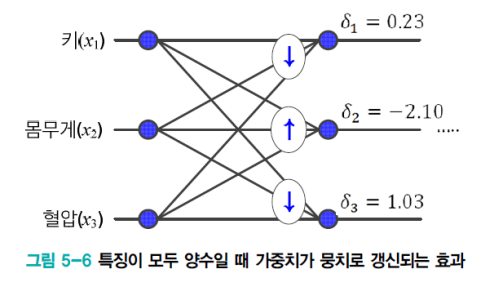
- 위 그림에서 ↑ 표시된 가중치는 모두 증가한다.
- 또한 ↓ 표시된 가중치는 모두 감소한다.
- 위의 예제에서 키, 몸무게, 혈압이 모두 양수일 경우
- Output Gradient에 의해서 연결되는 모든 가중치들의 증감이 계속 왔다 갔다 하게 된다.
- Gradient 가 (+) 이면 (-)가 되었다가 다시 (+) 이 되었다가 다시 (-) 이 되는 것을 반복한다.
- 가중치가 뭉치로 증가 또는 감소하면 최저점을 찾아가는 경로가 갈팡질팡하여 느리게 수렴된다.
이때 정규화 가 규모 문제와 양수문제를 해결해준다.
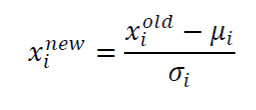
- 이는 특징별로 독립적이게 적용이 된다.
- 축을 바꿔서 평균을 바꾸고, 표준편차를 바꿔서 퍼짐의 정도를 바꾼다.
- 평균이 0이 되도록 변환하고, 표준편차가 1이 되도록 변환한다. (정규분포 z Transform)
명칭 값 (Norminal Value)을 원핫코드(One -hot)로 변환
명칭 값(명목변수) Norminal Value
- 객체 간 서로 구분하기 위한 변수이다.
- 예) 성별: 남(1), 여(2) // 체질: 태양인 (1), 태음인(2), 소양인(3), 소음인(4)
- 명목 변수는 거리의 개념이 없다.
원핫코드 (One- hot)
- 원핫 코드 값의 개수만큼 bit를 부여
- 예) 성별은 2비트를 부여, 체질은 4비트를 부
- 예) 키 1.755m, 몸무게 65.5kg, 혈압 122, 남자, 소양인 샘플
- (1.755, 65.5, 122, 1, 3) -> (1.755, 65.5, 122, [1, 0], [0, 0, 1, 0])
대칭적 가중치
대칭적 가중치 문제
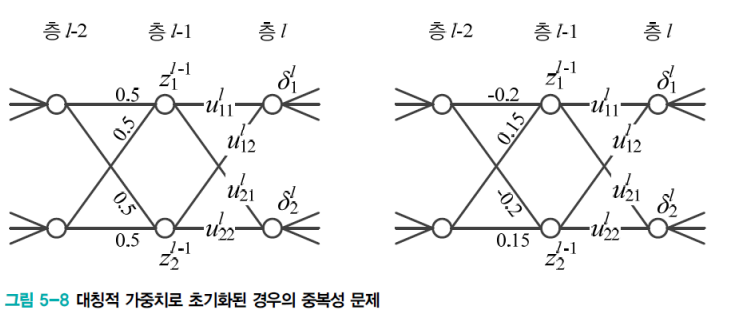
- 층과 층 사이에 모든 값들이 대칭적으로 연결되어 있는 경우
- 동일한 값으로 세팅되어 있는 극단적인 경우
- 이러한 두 가지 경우에 중간 Representation 값들이 서로 동일한 값이 되어버린다.
- 모든 노드가 똑같은 갱신을 중복하게 된다.
- 즉 두 노드가 같은 일을 하는 중복이 발생한다.
- 이를 해결하기 위해서 난수를 초기화함으로써 대칭을 파괴
- 대칭성을 없애서 층과 층 사이의 값들을 서로 다른 값으로 만든다.
난수로 가중치를 초기화
- 가우시안 또는 균일 (Uniform) 분포에서 난수를 추출한다.
- 두 분포의 성능 차이는 거의 없다.
- 하지만 난수의 범위는 무척 중요하다.

- 다음 두 식중에 하나로 r을 결정한 후에 [-r , r] 사이에서 난수를 발생시킨다.
- 노드로 들어오는 에지의 개수 nin과 노드에서 나가는 에지의 개수 nout라고 한다.

- 편향 ( 바이어스 )는 보통 0으로 초기화한다.
예시를 들어보자면 다음과 같다.

하지만 여기에서도 주의해야 할 점이 있다.
- 초기화가 너무 작으면, 모든 활성 값이 0이 된다.
- Back Propagation 시 경사도도 0이 되어서 학습이 되지 않는다.
- 초기화가 너무 크면 활성화 함수의 값이 포화된다.
- Back Propagation 시 경사도가 0이 되어 학습이 되지 않는다.
- 초기화가 적당하면, 모든 층에서 활성 값의 분포가 좋아진다. (적절한 학습)
모멘텀
경사도(그래디언트)의 잡음 현상
- 기계학습은 훈련 집합을 이용하여, 매개변수의 경사도를 추정하므로 잡음 가능성이 높다.
- 관성 모멘텀은 경사도에 부드러움(스무딩)을 가하여 잡음의 효과를 줄인다.-> 이를 통해서 수렴 속도 향상
- 이때 관성이란 과거에 이동했던 방식을 기억하면서 기존 방향으로 일정 이상 추가 이동하는 것
- 이렇게 되면 수렴 속도 향상이 된다.
- 또한 Local Minima , Saddle Point에 빠지는 문제를 해소한다.
모멘텀을 적용한 가중치 갱신 수식
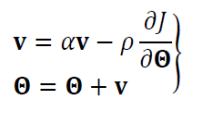
- 속도 벡터 v는 이전 경사도를 누적한 것에 해당한다.
- 처음에는 v = 0으로 출발한다.
- α의 효과 (관성의 정도)
- α = 0 이면 관성이 적용 안된 이전 경사도 갱신 공식과 동일하다.
- α 가 1에 가까울 수 이전 경사도 정보에 큰 가중치를 주는 셈이다.
-
모멘텀의 효과
- 지나침 (overshooting) 현상을 누그러뜨린다.
- 즉, 지그재그를 완화시킨다.
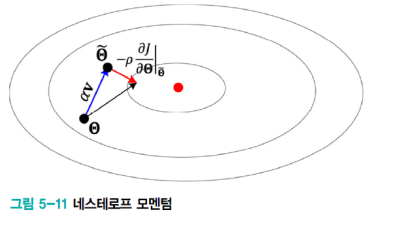
네스테로프 모멘텀
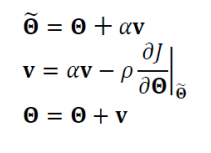
- 현재 v 값으로 다음 이동할 곳 Θ을 예견한 후, 예견한 곳의 경사도를 사용한다.
- 이는 멈춤에서의 용이하다.
- 모멘텀을 적용한 가중치 갱신은
- 그래디언트를 구하고 과거의 경사도를 누적한 걸 바탕으로 Θ값을 갱신한다.
- 네스테로프 모멘텀 가중치 갱신은
- 현재 v값을 구할 때 다음 값으로 이동시켜놓고 (세타 값을 예견한다)
- 이동시켜 놓은 것에서부터 경사도를 구한다.
- 이동시켜놓고 그래디언트를 구하기 때문에 수렴이 더 잘되고 멈춤도 더 쉽다.
적응적 학습률
학습률
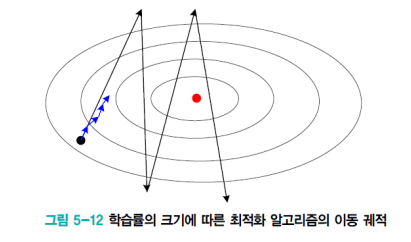


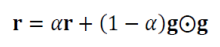
- α가 작을수록 최근 것에 비중을 둔다.
- 보통 α로 0.9, 0.99,0.999를 사용한다.
- RMSProp + Momentum 인 방법이다.
- RMSProp에 관성을 추가로 적용한 알고리즘이라고 할 수 있겠다.
- Adam을 신경망에서 Optimizer로 많이 사용한다.
활성함수

- 활성함수를 변화시켜서 성능향상을 노렸다.
- 시그모이드 함수
- 활성값이 높아지면
- 그래디언트는 0으로 수렴한다. (그래디언트 소멸 현상)
- 포화상태가 된다.
- 매개변수의 갱신 (학습) 이 매우 느려진다.
- 활성값이 높아지면
- ReLU 활성함수
- 포화문제를 해결했다
- y = ReLU(z) = max(0,z)
- z < 0: gradient 의 값이 0이다.
- z >= 0 : gradient 의 값이 일정 상수값이 나온다.
- Leaky ReLU / PReLU
- LeakyReLU(z)
- z < 0 : az
- z >= 0: gradient 가 일정한 상수값이 나온다. (보통은 같은 z 값이 나온다.)
- 보통 a의 값을 0.01을 사용한다.
- PReLU
- a의 값을 학습으로 알아낸다.
- LeakyReLU(z)
- Softplus
- z <0 인부분의 그래디언트 값이 0 이 아니다.
- 시그모이드 함수
규제의 필요성과 원리
과소적합과 과대적합
- 모델의 표현용량이 작다 -> 과소적합 (Underfitting)
- 모델의 표현용랴잉 크다 -> 과대적합 (Overfitting)
- 과잉적합에 빠지는 이유
- 가지고 있는 데이터보다 모델의 용량이 더 클때
- Overfitting 가능성이 크다
- 따라서 규제화가 필요하다.
- 가지고 있는 데이터보다 모델의 용량이 더 클때
학습 모델의 용량에 따른 일반화 능력
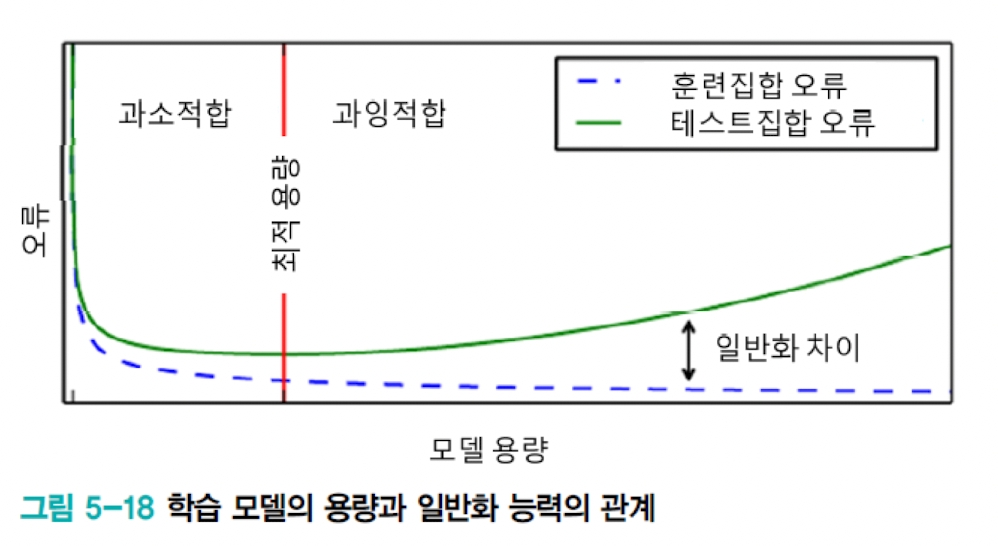
- 대부분 가지고 있는 데이터에 비해서 훨씬 큰 용량의 모델을 사용
- 훈련집합을 단순히 암기하는 과잉적합에 주의를 기울여야 한다.
- 현대 기계학습의 전략
- 충분히 큰 용량의 모델을 설계한다.
- 학습과정에서 여러 규제 기법을 적용한다.
규제의 정의
- 규제는 수학과 통계학에서도 연구해온 주제
- 모델 용량에 비해서 데이터가 부족한 경우의 불량 문제를 푸는데 사용
- 적절한 가정을 투입해서 문제를 푼다.

- 티호노프의 규제기법은 매끄러움 가정에 기반을 둔 식을 사용
- 명시적 규제와 암시적 규제
- 명시적 규제: 가중치 감쇠나 드롭아웃처럼 목적함수나 신경망 구조를 직접 수정하는 방식이다.
- 암시적 규제: 조기 멈춤, 데이터 증대, 잡음 추가, 앙상블처럼 간접적으로 영향을 미치는 방식이다.
가중치 벌칙
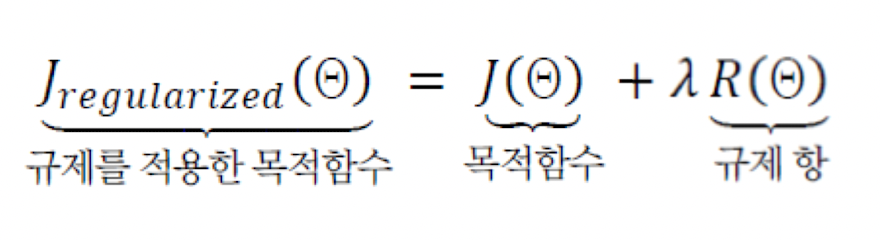
- 규제항은 훈련집합과 무관하며, 데이터 생성 과정에 내재한 사전 지식에 해당한다.
- 규제항은 매개변수를 작은 값으로 유지하므로 모델의 용량을 제한하는 역할을 한다.
- 즉 수치적 용량을 제한한다.
이때 규제항을 무엇으로 사용할 것인가?
- 큰 가중치에 벌칙을 가해서 작은 가중치를 유지하려고 주로 L2 놈, L1 놈을 사용한다.
L2 놈
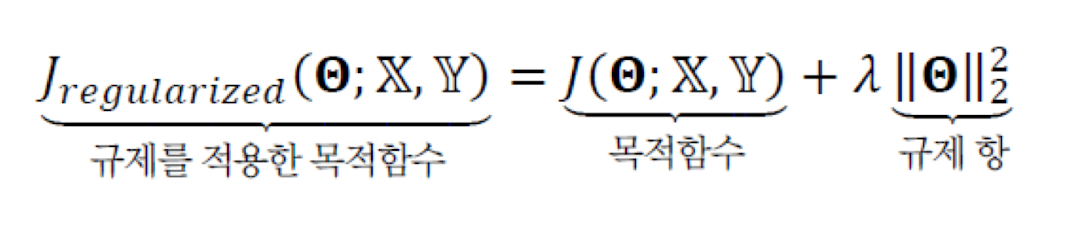
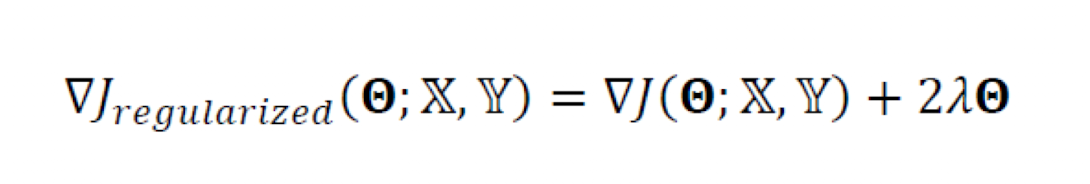

- 가중치 벡터에 L2놈을 사용하는 것은 그 벡터(가중치)의 크기를 재는 것이다.
- 규제항 R로 L2놈을 사용하는 규제 기법을 '가중치 감쇠' 라고 부른다.
- λ= 0 으로 둔다면, 규제를 적용하지 않는것이다.
- 가중치 감쇠는 단지 Θ에

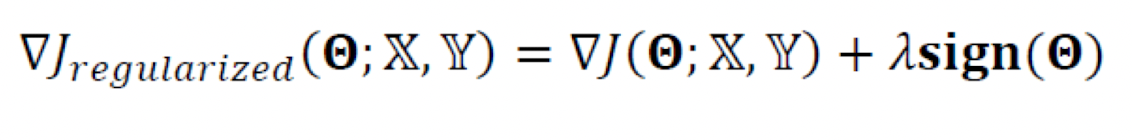
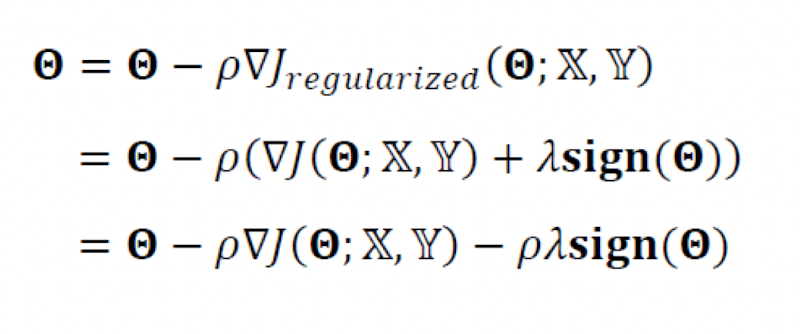
- 희소성 효과
- 0이 되는 매개변수들이 많아진다.
- 즉 어떠한 것들은 고려하지 않아도 된다.
- 선형회귀 적용
- 특징 선택효과가 있다
- 즉 어떤게 더 중요한지 결정할 수 있다.
조기멈춤
- 학습시간이 일정시간이 지나면 과잉적합 현상이 나타난다.
- 이는 일반화 능력이 저하된다.
- 검증집합의 오류가 최저인 점에서 학습을 멈춘다.
데이터 확대
- 과잉적합을 방지하는 가장 확실한 방법은 큰 훈련집합을 사용하는것이다.
- 하지만 데이터 수집은 비용이 많이 드는 작업이다.
- 데이터 확대라는 규제기법은
- 데이터를 인위적으로 변형하여 확대하는 방법이다.
- 한계
- 수작업으로 변형을 해줘야 한다.
- 모든 부류가 같은 변형을 사용한다.
드롭아웃
- 노드의 일정비율을 임의대로 선택해서 제거한다.
- 남은 부분을 신경망으로 학습한다.
- 많은 부분신경망을 앙상블 결합으로 학습한다.
- 이는 계산시간과 메모리의 공간을 많이 차지한다는 단점이 있다.
앙상블
- 서로다른 여러개의 모델을 결합하여 일반화 오류를 줄이는 기법이다.
- 현대의 학습은 앙상블도 규제로 여긴다.
- 서로다른 예측기를 학습해 결합한다. (투표방식 사용)
하이퍼 매개변수 최적화
- 내부 매개변수
- 신경망에서는 에지 가중치로 Θ 라고 표기한다.
- 학습 알고리즘이 최적화한다.
- 하이퍼 매개변수
- 모델 외부에서 모델의 동작을 조정한다.
- 은닉층, 구조, 노드개수, 모멘텀, 학습률
- 보통은 제시하는 기본값을 사용한다.
- 즉 우리는 하이퍼매개변수 후보중 주어진 데이터에 최적인 값을 선택하면 된다.
하이퍼 매개변수 최적화 방식
- 격자 탐색
- 주어진 예산에 맞게 짤라서 비교한다.
- 임의 탐색
- 난수로 매개변수를 조합한다.
로그규모 간격
- 어떠한 매개변수는 로그 규모를 사용해야 한다.
- 학습률에 많이 적용이 된다.
차원의 저주
- 매개변수가 많게되면 탐색점이 많아진다.
임의탐색 우월함
'STUDY > 인공지능' 카테고리의 다른 글
| #11. RNN (0) | 2022.11.28 |
|---|---|
| #10. CNN (0) | 2022.11.28 |
| #8. Pytorch 실습 (0) | 2022.11.01 |
| #7. 딥러닝과 깊은 퍼셉트론 (0) | 2022.11.01 |
| #6. 다층 퍼셉트론 및 딥러닝 기초 (0) | 2022.11.01 |




